NVIDIA rules the performance roost, Qualcomm demonstrates exceptional power efficiency, and Intel demonstrates the power of software.
Every three months, the not-for-profit group MLCommons publishes a slew of peer-reviewed MLPerf benchmark results for deep learning, alternating between training and inference processing. This time around, it was Inference Processing V1.1. Over 50 members agree on a set of benchmarks and data sets they feel are representative of real AI workloads such as image and language processing. And then the fun begins.
From what I hear from vendors, these benchmarks are increasingly being used in Requests for Proposals for AI gear, and also serve as a robust test bed for engineers of new chip designs and optimization software. So everyone wins, whether or not they publish. This time around NVIDIA, Intel, and Qualcomm added new models and configurations, and results were submitted from Dell, HPE, Lenovo, NVIDIA, Inspur, Gigbyte, Supermicro, and Netrix.
And the winner is…
Before we get to the acccelerators, a few comments about inference processing. Unlike training, where the AI job is the job, inference is usually a small part of an application, which of course runs on an x86 server. Consequently, Intel pretty much owns the data center inference market; most models perform quite will on Xeons. Aware of this, Intel has continually updated the hardware and software to run faster to keep those customers happy and on the platform. We will cover more details on this in a moment, but for models requiring more performance or dedicated throughput for more complex models, accelerators are the way to go.
On that front, Nvidia remains the the fastest AI accelerator for every workload, on a single chip basis. On a system level, however, a 16-card Qualcomm delivered the fastest ResNet-50 performance with 342K images per second, over an 8-GPU Inspur server at 329K. While Qualcomm increased their model coverage, Nvidia was the only firm to submit benchmark results for every AI model. Intel submitted results for nearly all models in data center processing.
Qualcomm shared results for both the Snapdragon at the edge, and the Cloud AI100, both offering rock solid performance with absolute leadership power efficiency across the board. Here’s some of the data.
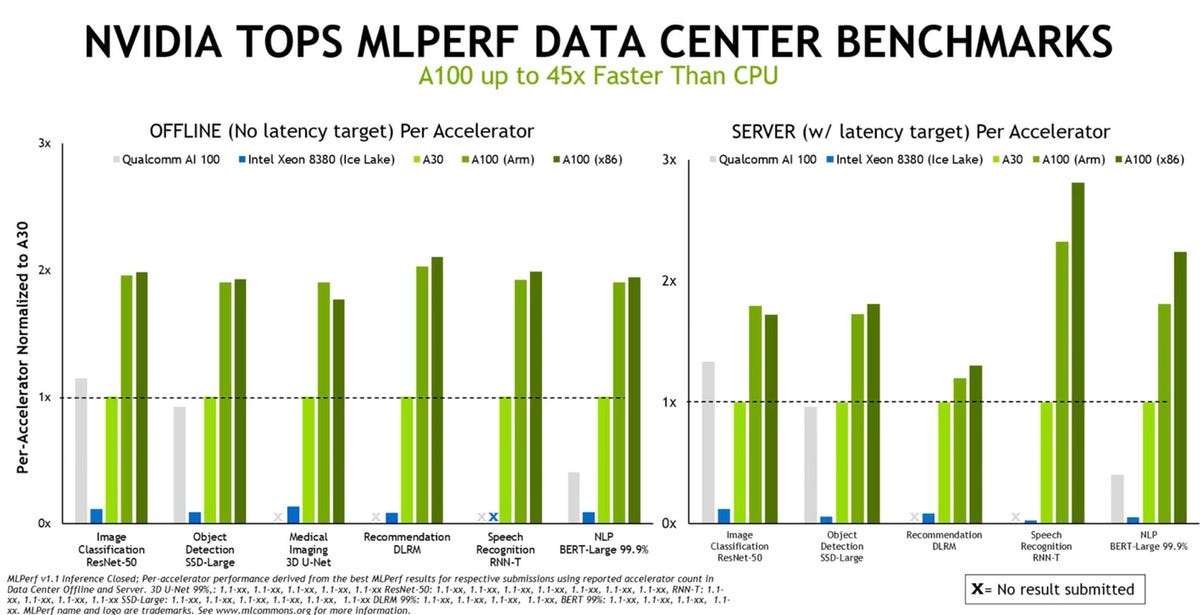
Nvidia, as usual, clobbered the inference incumbant, which is the Intel Xeon CPU. Qualcomm out-performed the NVIDIA A30, however. Nvidia
Every year, Nvidia demonstrates improved performance, even on the same hardware, thanks to continuous improvements in its software stack. In particular, TensorRT improves performance and efficiency by pre-processing the neural network, performing functions such as quantization to lower-precision formats and arithmetic. But the star of the Nvidia software show for inference is increasingly the Triton Inference Server, which manages the run-time optimizations and workload balancing using Kubernetes. Nvidia has open-sourced Triton, and it now supports x86 CPUs as well as Nvidia GPUs. In fact, since it is open, Triton could be extended with backends for other accelerators and GPUs, saving startups a lot of software development work.
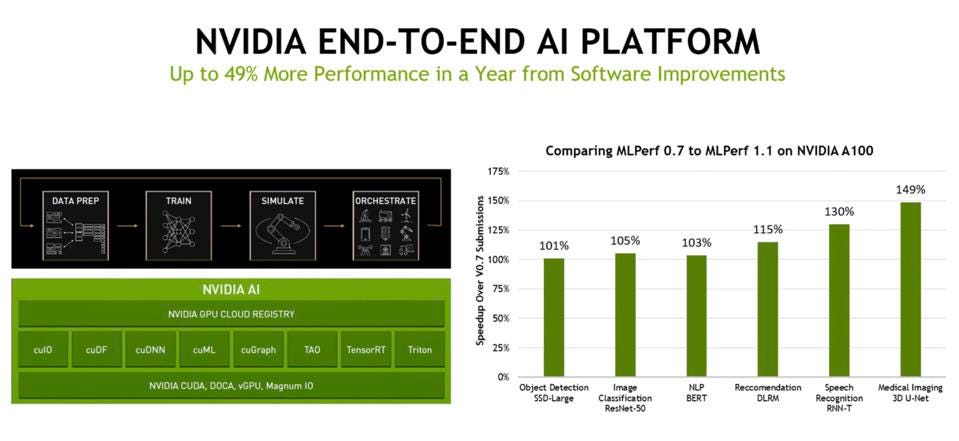
Nvidia demonstrated nearly 50% better performance over results from a year ago, all based on improved software especially for newer AI models such as medical imaging and speech recognition. Nvidia
In some applications, power efficiency is a critical factor for success, but only if the platform achieves the required performance and latency for the models being deployed. Thanks to years of research in AI and Qualcomm’s mobile processor legacy, the AI engines in Snapdragon and the Cloud AI100 deliver both, with up to half the power per transaction for many models versus the Nvidia A100, and nearly four times the efficiency of the Nvidia A10.
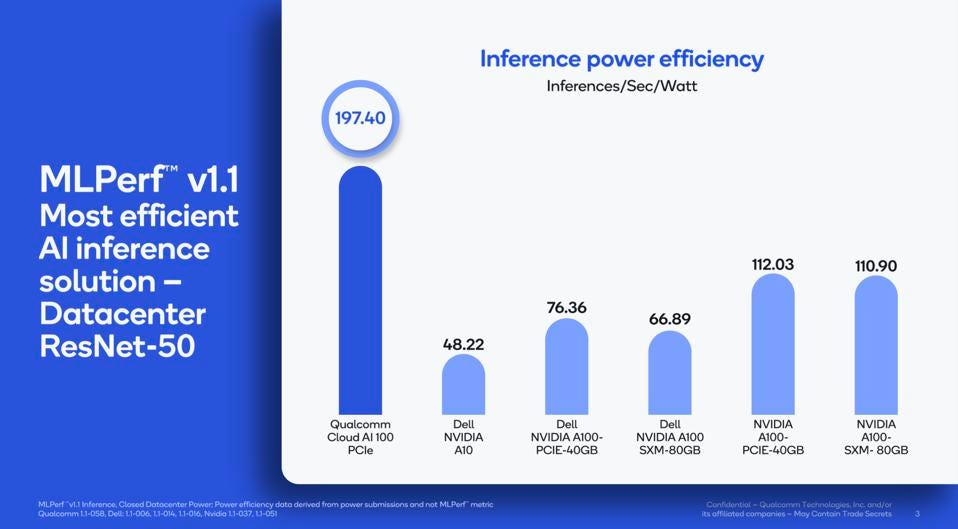
Qualcomm Cloud AI100 offered the best performance per watt of all other submissions. Qualcomm
Back to Intel, the new Ice Lake Xeon performed quite well, with up to 3X improvment over the previous Cooper Lake CPU for DLRM (recommendation engines), and 1.5X on other models. Recommendation engines represent a huge market in which Xeon rules, and for which other contenders are investing heavily, so this is a very good move for Intel.
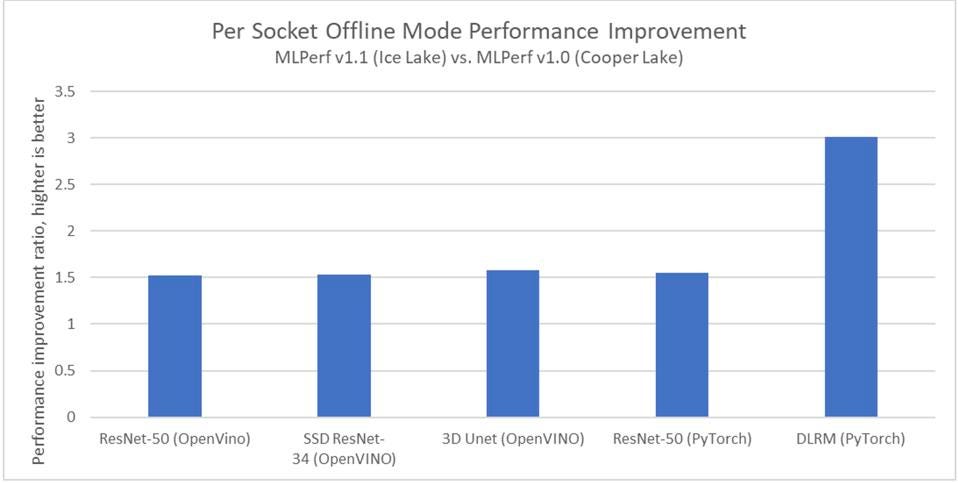
Intel demonstrated 50%-300% better performance with Ice Lake vs, the previous Cooper Lake results. This was accomplished in part by the improvements the engineering team has realized in the software stack. Intel
Intel also demonstrated significant performance improvements in the development stack for Xeon. The most dramatic improvement was again for DLRM, in which sparce data and weights are common. In this case, Intel delivered over 5X performance improvement on the same hardware.
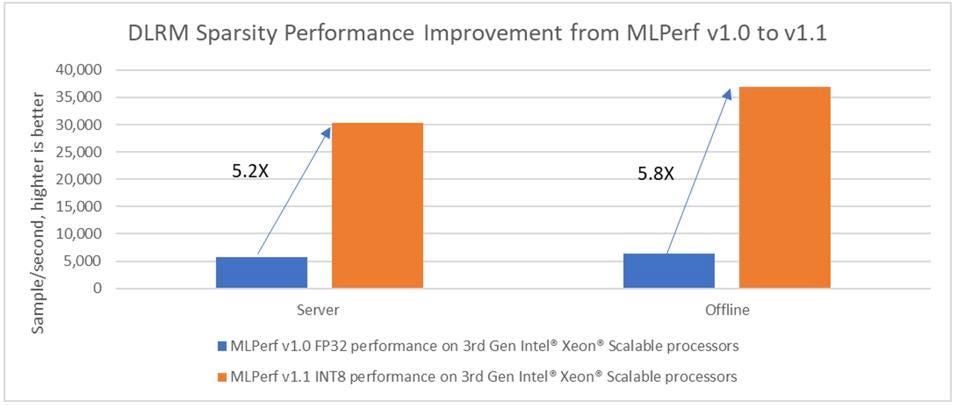
Intel shared the five-fold performance improvement from sparsity, on the same chip. Intel
Conclusions
As followers of Cambrian-AI know, we believe that MLPerf presents vendors and users with valuable benchmarks, a real-world testing platform, and of course keeps analysts quite busy slicing and dicing all the data. In three months we expect a lot of exciting results, and look forward to sharing our insights and analysis with you then.