When we explored the eight “AI Firsts” from Qualcomm AI Research earlier this year, it was clear to us the company’s full-stack approach to AI ensured that many of the innovations under investigation would translate to superior platforms for 5G, the edge, and the data center. Now the organization is tackling the next big challenge: 3D Perception.
One of the thorniest problems mobile and edge platforms wrestle with is achieving 3D perception on 2D images or 3D point clouds using an energy-efficient platform like Snapdragon. Now the company is the first to demonstrate 3D perception proof-of-concepts on edge devices and is working to solve system and feasibility factors to move from research to commercialization. This article explores the problems and solutions addressed by Qualcomm AI Research to evolve 3D perception.
The Benefit of 3D over 2D perception
3D perception offers many benefits over 2D, as a 3D point cloud is a more reliable model of reality and provides confident cues for object detection and scene recognition, which is essential in robotic and autonomous vehicles. 3D can also provide accurate size, pose, and motion estimation as well as enable realistic rendering from light and radio frequency signals.
Qualcomm AI Research has initially focused on 4 areas of 3D perception: depth estimation, pose estimation, object detection, and scene understanding. In all four areas, described in Figure 1, Qualcomm AI Research has applied novel AI techniques, such as using transformer models, with an eye toward power-efficient real-world deployment by considering the full stack optimizations, not just the hardware to accelerate the computation. We would note that this is consistent with the recently announced Qualcomm AI Stack and expect these innovations to be added to that framework.

Current research areas on 3D perception underway at Qualcomm Technologies.Qualcomm
Implementing these concepts is technically difficult mathematically, but especially so in the thermal- and power-constrained environments Qualcomm creates for mobile and edge devices. Consequently, the research team must constantly find ways to do computation more efficiently while maintaining accuracy. This is especially true when applying transformers, which are incredibly powerful but are also computationally hungry models built on massive networks of parameters. Useful techniques here include exploitation of sparsity, dealing with incomplete data sets, quantization, and self-supervised training of AI models.
Depth Estimation
Self-supervised training is used in estimating depth from unlabeled monocular videos utilizing geometric relationships across video frames. Qualcomm AI Research has developed a novel transformer architecture that leverages “spatial self-attention” for depth estimation, with a smaller model that runs in real-time and impacts only the training process, requiring no additional inference computations. In fact, this technique has resulted in a model that is 26 times smaller and runs in real-time on the Snapdragon’s Hexagon Processor.
Beyond monocular videos, Qualcomm AI Research has developed stereo depth estimation models for increased accuracy, similar to human visual perception. These stereo techniques enable real-time estimation on a phone on today’s Hexagon Processor with greater generalizability, increased precision, and over 20-times faster than the current state of the art (SOTA).
Object Detection
Enabling efficient and accurate 3D object detection is critical for understanding the physical world. Qualcomm AI Research has developed a transformer-based architecture that reduces latency and memory usage without sacrificing accuracy. And the model can function without requiring a complete and expensive 360 LiDAR scan. The remarkable results show a model that is more accurate, faster, uses a fraction of the parameters of SOTA models in use today, all while consuming far less computation and energy.
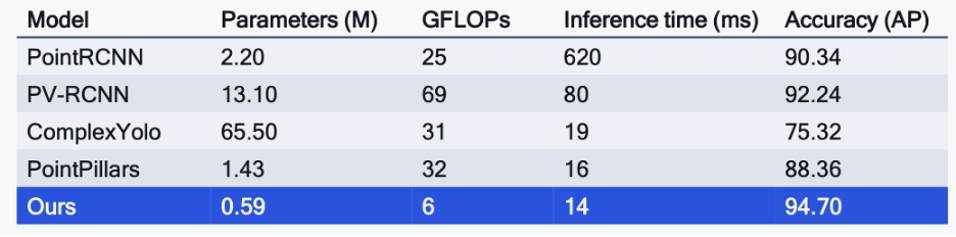
Qualcomm has measured their object detection algorithm performance versus the state of the art. Qualcomm
Pose Estimation
Inferring human pose, whether it be head, body, or hands, is important for many 3D applications. Interestingly[A1] , Qualcomm AI Research has developed a lightweight architecture that recursively refines estimation of hand poses in real time without the need for precise hand detection or massive computation. The technique incorporates attention and gating for dynamic refinement, again delivering a power and memory efficient algorithm. This approach could be used in augmented or virtual reality experiences as well to someday facilitate communications between the deaf, translating American Sign Language to text, or audio for those who can hear. And one can imagine all this running on a Snapdragon-based edge device.

In this example, Qualcomm uses dynamic refinements to recognize hand poses. Qualcomm
Scene Understanding
Scene understanding decomposes a scene into its 3D and physical components. In yet another industry first, Qualcomm AI Research has developed another transformer-based model that can use “inverse rendering” to estimate scene attributes from a 2D image. This model could be used to create meta data about a scene, such as room layout, surfaces, albedo, materials, objects and lighting estimation. This could lead to better interactions between scene components, disambiguating shapes, materials, and lighting. This SOTA 3D scene understanding could enable high-quality AR applications, such as 3D object insertion into a real-world scene without spatial conflicts.
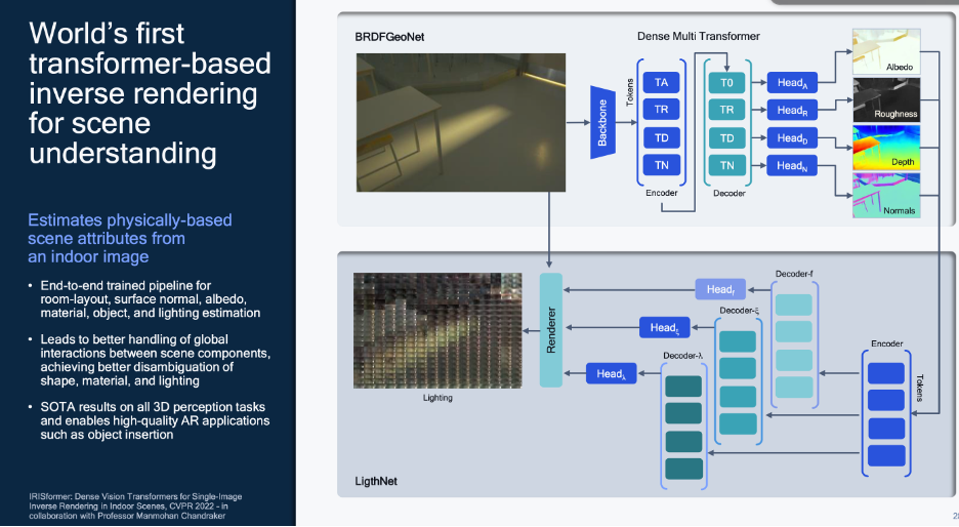
Qualcomm has developed a transformer model to enable scene understanding. Qualcomm has developed a transformer model to enable scene understanding.Qualcomm
What could be next?
Qualcomm AI Research is engaged in a menu of interesting projects and look forward to sharing performance advances in the future. One of the more intriguing and valuable of these is called Neural Radiance Fields (NeRFs). NeRFs can be used to create virtual images from any viewpoint, an astonishing scene at which we have all marveled when watching TV coverage of a football game. But instead of programming an FPGA to accomplish this visually amazing feat, Qualcomm believes their approach can run in real-time on a Snapdragon-based mobile device.
In other endeavors, Qualcomm is researching “3D imitation learning” to enable robots to someday be able to mimic a dexterous motion using a video of a human maneuver. Neuro-SLAMs could be another innovation, enabling 3D mapping of interior spaces to facilitate XR, autonomous vehicles, and robotic vision with real-time 3D maps. And finally, Qualcomm AI Research is working on 3D scene understanding using RF signals, which could enable floorplan estimation, human detection, tracking, and pose using only RF signals.
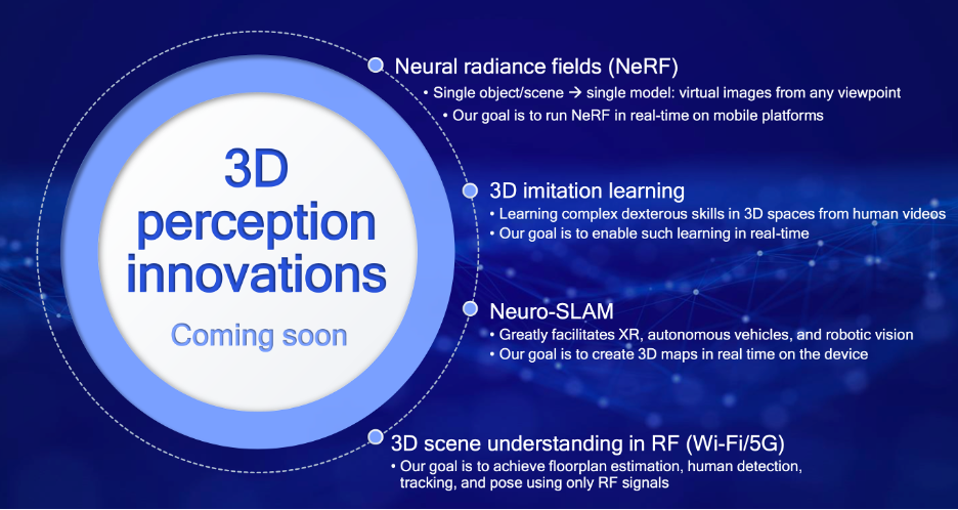
Some projects in the works show that Qualcomm AI Research is leading the industry in AI for 3D perception.Qualcomm
Conclusions
These new 3D perception techniques go far beyond simply satisfying an engineer’s penchant for creativity and curiosity. 3D perception lies at the very heart of solving critical real-world problems from autonomous vehicles and more efficient factories to saving lives on the operating table. These approaches are excellent examples of useful creativity being applied at Qualcomm AI Research to be at the heart of the connected intelligent edge enabled by smart devices that we can all afford and use in an intuitive ways. We know of no other company who is tackling these problems as quickly and as effectively as Qualcomm AI Research.