After delays, the company now has working silicon back from TSMC, with high power efficiency for recommendation engines.
Esperanto has announced more details at Hot Chips about its much-anticipated AI accelerator designed for power-efficient inference processing. Founded by Dave Ditzel, a co-inventor of RISC and founder and CEO of Transmeta, Esperanto initially received a lot of attention back in 2017 in association with its work with Facebook and RISC-V open source CPU. Since then, the company has been quietly heads-down, designing and implementing a completely new form of AI acceleration silicon using those RISC-V cores. To get the company to the next level, the board has brought in Art Swift, formerly with Transmeta, MIPS, and Wave Computing, as CEO.
The initial focus for the new Esperanto ET-SoC-1 will be in the hot market for recommendation engines for e-commerce and social media firms, but the company sees other opportunities emerging in edge AI as well. The first chip is back in-house and being brought up now, so we are probably looking at product availability in 2022, and of course all performance and power data today are estimates from simulations and hardware emulation.
Performance and Efficiency
Let’s look at the chip’s performance and power efficiency. Esperanto shared both image processing and recommendation MLPerf benchmarks for a six-chip card versus the low end NVIDIA A10 and the older T4, and against these stalwarts it looks pretty impressive. Since there are as yet no real incumbents for accelerated recommendations, this power efficiency will be attractive to eCommerce companies. Again, these are estimates from simulation and hardware emulation.
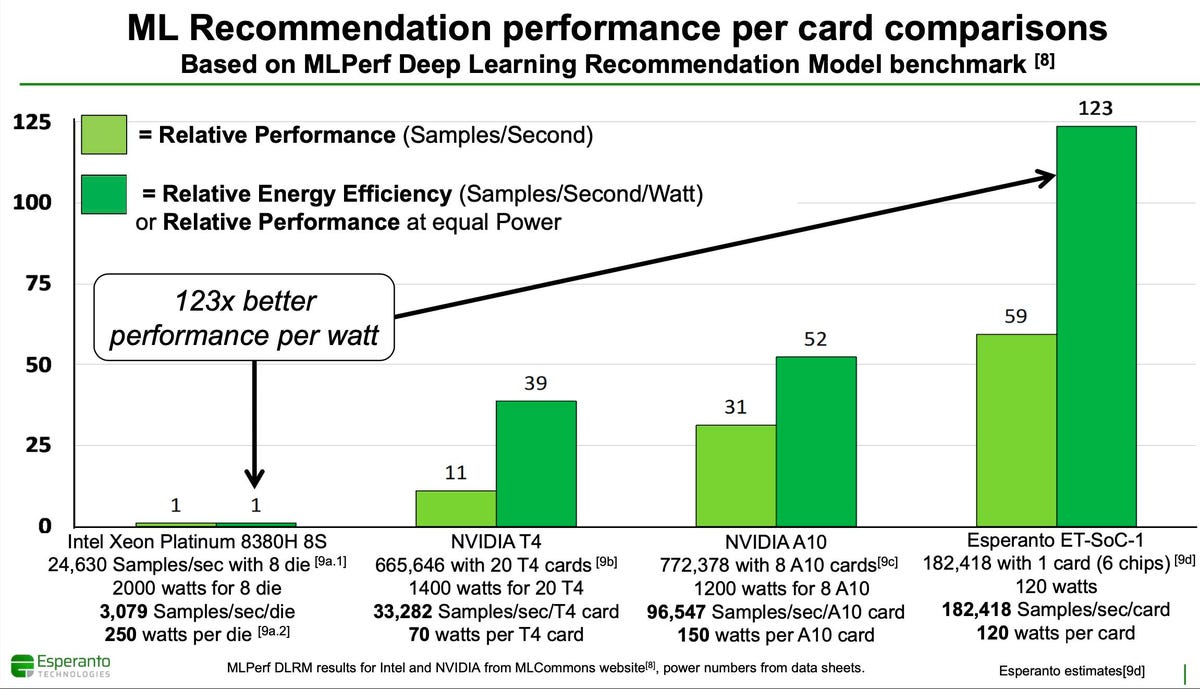
Looking at the performance and efficiency of the new Esperanto chip for recommendation engines shows a strong story. source: Esperanto
Unfortunately, the most power-efficient chip we know of, the Qualcomm Technologies Cloud AI100, has not yet published this benchmark. But I applaud the Esperanto team for putting a real benchmark on the board, not just a TOPS number. Note that the power numbers above are TDP from data sheets, not at-the-wall power measurements.
Why RISC-V?
RISC-V is the open-source implementation of RISC CPU cores, designed for low power computing typically in embedded applications. This is the first and fastest RISC-V design we have seen for high-performance data center workloads. Esperanto selected this approach because the design team wanted to extend the RISC cores with AI features such as vector processing units, and because the software stack for RISC-V is progressing nicely. Arm could have been an option, but Arm cores are too large for a design such as the ET-SoC-1. And of course customizing Arm cores requires an expensive architectural license.
There is another important benefit of using RISC cores instead of a custom array of multiply/accumulate cores as others have done. All AI startups struggle with the need to design custom computational kernels that are optimized for the unique architecture at hand. This is a job for Ninjas only, typically the hardware designers themselves do this work. But since Esperanto uses RISC-V instruction set, and since the architecture is open and widely understood, we would anticipate the company will be able to engage the community to develop these special routines. Not only will this save Esperanto engineering effort, they should be able to recruit a lot of help from their prospective clients.
We look forward to examining the details of the Esperanto chip in the near future. From the HotChips presentation, one can see they have engineered a new memory architecture that should support the huge tables needed for recommendation prediction.
Conclusions
While the Esperanto chip looks very power efficient, the delays the company experienced will impact its competitive position. Companies like Qualcomm Technologies are already shipping AI inference processors with up to 12 TOPS per watt for their lowest power SKU. Of course TOPS doesn’t factor in the benefits of memory and networking optimizations Esperanto has developed. I know you are tired of hearing me say this, but it will all come down to the software, which we don’t know a lot about as of yet, and down to real application performance such as the rest of the MLPerf suite. So, once again, stay tuned!