The Qualcomm AI chip also looks pretty efficient, but where is everyone else?
MLCommons, the not-for-profit organization that manages the AI benchmarks collectively known as MLPerf, has just released the V1.0 inference results. While NVIDIA once again dominated the field, it is somewhat of a hollow victory given the lack of competitive submissions. In fact, only three AI accelerators shared results. NVIDIA submitted results in every category, while Qualcomm offered just a few. Let’s examine what the benchmarks tell us, and consider possible reasons for the lack of wider participation.
Note that these are the first MLPerf results to include power metrics, and the first for the Qualcomm Cloud AI100 which began shipping last September.
NVIDIA Results
NVIDIA used the results to tout several advantages. First, NVIDIA was the only company to run every benchmark in the AI suite. The recently announced NVIDIA A10 and A30 GPUs, which target energy-constrained enterprise data centers, perform quite well at 150 and 165 watts TDP, compared to the 250- and 400-watt A100.
Second, NVIDIA performed well in both their traditional stronghold, the data center, as well as the fast-growing market for AI at the edge. However, as we shall see, the Qualcomm Cloud AI100 product produced some excellent results when one factors in the energy consumption at the edge.
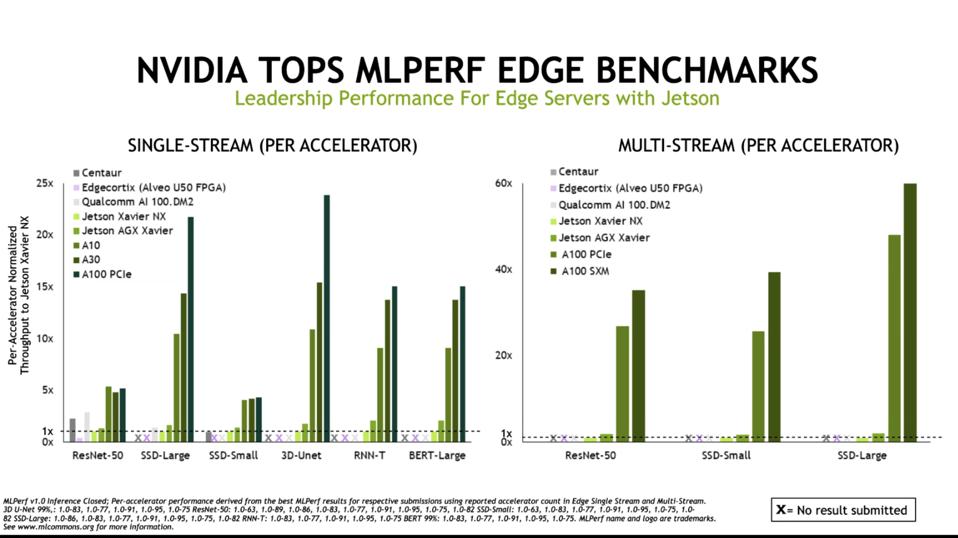
Similarly, NVIDIA outperforms the few brave contenders in Edge AI benchmarks, Xilinx and Qualcomm. Results are normalized to the NVIDIA Jetson Xavier NX. NVIDIA
Third, NVIDIA ran benchmarks using the Multi-Instance GPU (MIG) feature on the A100, demonstrating that MIG provides an efficient platform for inference processing. In fact, overhead is minimal, as the benchmarks realized 98% of the single MIG performance while running AI benchmarks on the other six instances. This validates what we’ve been asserting, that large cloud service providers and social media sites can and will use the A100 MIG to simplify their AI infrastructure for inference and training, running both on the NVIDIA A100 instead of deploying smaller GPUs like the NVIDIA T4 for inference work.

NVIDIA’s Multi-Instance GPU allows up to seven workloads to run simultaneously on a single chip with little to no overhead compared to a single instance MIG. NVIDIA
Qualcomm delivers outstanding efficiency, but no design wins.
The MLPerf V1.0 release is the first time to include power metrics, measured as total system power over at least a ten minute run-time. While Qualcomm only submitted AI100 results for image classification and small object detection, the power efficiency looks good. The chip performs reasonably well, delivering up to 3X performance over the (aging) NVIDIA T4, while the more expensive and power hungry NVIDIA A100 roughly doubles the Qualcomm performance on a chip-to-chip basis, based on these limited benchmark submissions.
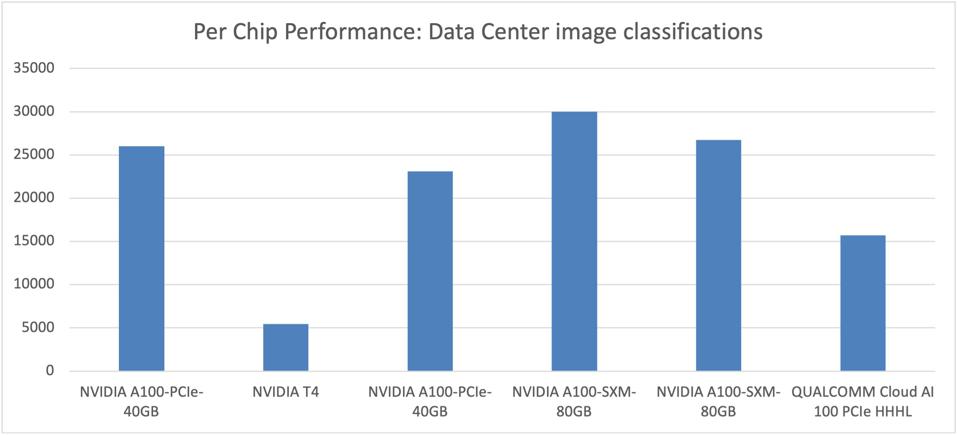
Looking at Per-Chip performance, the Qualcomm Cloud AI100 holds its own against far larger and more expensive NVIDIA products. Cambrian-AI Research Analysis
While NVIDIA still wears the performance crown, the new Qualcomm Cloud AI100 platform delivers up to 70% better performance per watt for some data center inference workloads, at least on image classification. These submissions were run on the Gigabyte AMD EPYC server we recently mentioned.
Qualcomm is targeting the “Cloud Edge” market and first-tier cloud service providers with this new platform. Inference processing is largely more price and power sensitive than data center training, so one would assume this platform would attract interest if the efficiency is more broadly evident. However, the Qualcomm part has not yet won any public endorsements. At this point, customers might opt to await a second generation (7nm) version, unless we see a major win soon. This could be a common trend as the Cambrian AI Explosion continues; the first part is really a test vehicle, and investors should factor that in to their expectations.
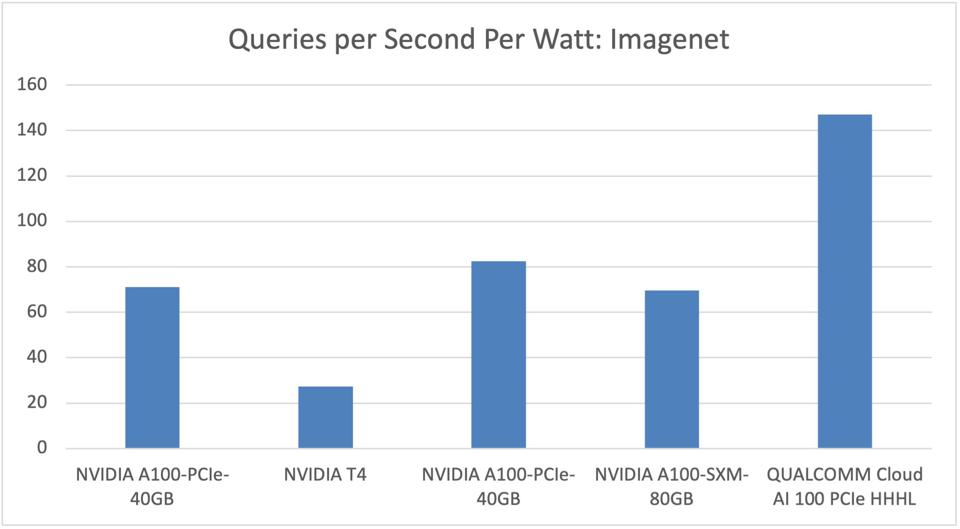
The Qualcomm AI part delivers 70% better power efficiency than NVIDIA. Cambrian-AI Research Analysis
In the edge, the Qualcomm Cloud AI100 DM.2e defeats NVIDIA AGX Xavier by over 3.5X at roughly the same system power (36 watts) in image classification, with 72% lower latency. We note however that the Jetson Xavier is a complete System-on-a-Chip (SoC), with Arm cores and other logic not available on the AI100, so this is a bit of an apples to pears comparison.
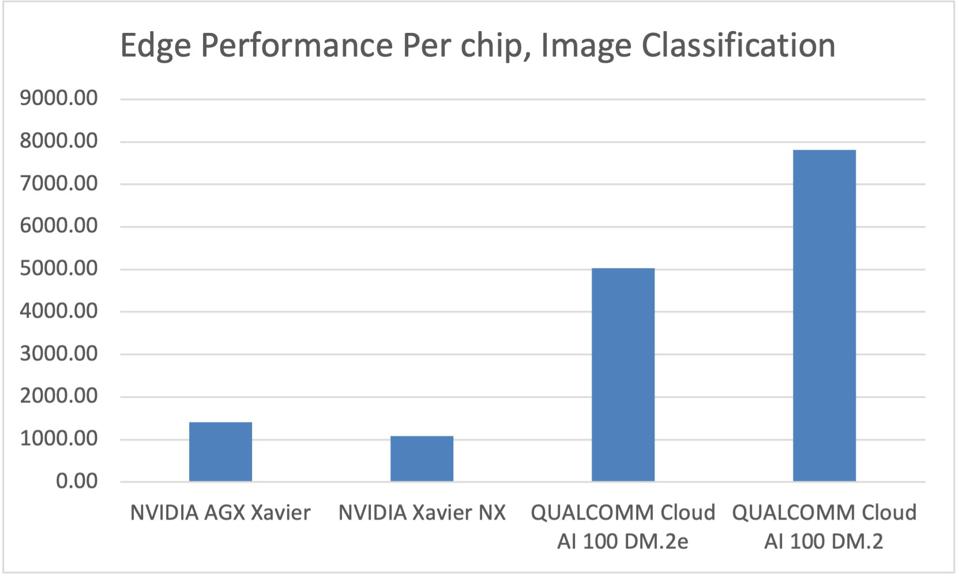
At the edge, Qualcomm demonstrates a significant performance advantage over NVIDIA Jetson Xavier … [+]Cambrian AI Research analysis
OK, so where the heck is everyone else?
It is indeed frustrating to see zero startups step up to the benchmarking plate. While it is easy to jump to the conclusion that their results must stink, there are other possible answers to consider. First, many AI startups such as Cerebras, Sambanova and Graphcore are targeting training, and these newly released benchmark results are for inference workloads. Hopefully we could see new training results in three months, but I suspect we will still be disappointed.
Companies targeting inference such as Groq, Blaize, and Tenstorrent do not see sufficient marketing value compared to the effort spent if they were to publish these benchmarks. They would prefer to spend time helping customers evaluate their platforms and work with the software, an understandable priority to say the least.
Moreover, NVIDIA is quick to point out that MLPerf has created open-source benchmarks that are representative of all the largest AI markets, and these benchmarks are used to evaluate and compare vendors’ performance. Chip companies all use MLPerf to assess their hardware and software, which helps them optimize current and future products.
Conclusions
We applaud MLPerf and the dozens of organizations that support the definition and application of these benchmarks. They have all done an excellent job of creating representative benchmarks that mirror real-world applications. The AI industry is still in its infancy, any industry-standard metrics are critical to both developers and users of AI silicon. We eagerly look forward to the next round of benchmarks, and would encourage all vendors to publish results as soon as their hardware and software platforms become stable.