What does Untether AI promise?
Untether AI recently emerged from stealth and described their architecture as being “At-Memory”, which the company claims will deliver leading performance and power efficiency. Most products that claim the latter deliver relatively weak performance (with the exception of Qualcomm’s CloudAI 100). This is because power generally does not scale linearly with respect to performance; twice the performance could demand four times the power.
Founded in 2018, and located in Toronto and Silicon Valley, the company has raised $170M to date. Notable investors include Intel Capital, which tells me that an experienced investor liked what they saw.
So, let’s look at the architecture. I like the chart below, as it clearly positions Untether AI versus cache-oriented Von Neumann designs. While interesting, the assertion that this architecture is unique is a bit of a reach: other startups have somewhat similar memory architectures, but few can claim the efficiency that Untether AI is demonstrating with early silicon. Each processing element has its own dedicated on-die memory for weights and activations, and the platform supports both SIMD on the ALUs and MIMD across the chip.
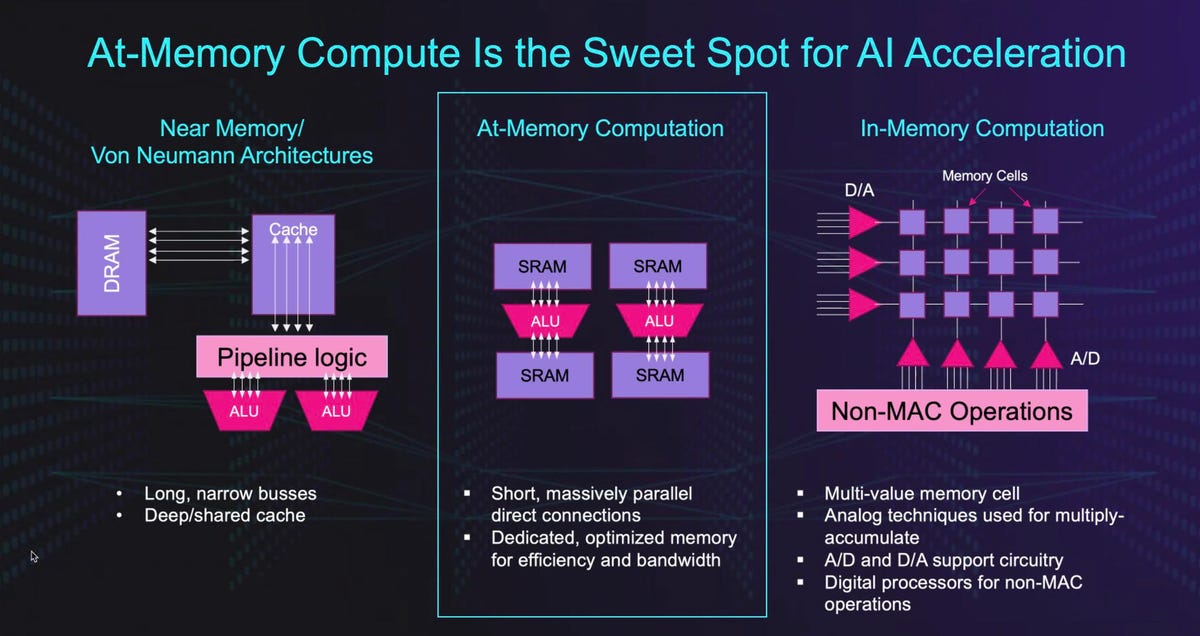
At Memory Computing is a new concept that Untether claims is a sweet spot for AI UntetherAI
Now, here’s the thing: Untether AI claims that its runAI200 chip will crank out over 500 Trillion Ops Per Second (TOPS) with 8-bit inference operations with 200MB of on-die SRAM, all at 8 TOPS/watt. That implies the chip consumes about 60 watts or so, while potentially cranking out 80% of the inference performance of the industry-leading NVIDIA A100, which consumes 300-500 watts. I say “potential” because this is all based on TOPS, not based on real application performance, which we hope to see soon. No mention was made of other numeric formats, which could represent a problem.
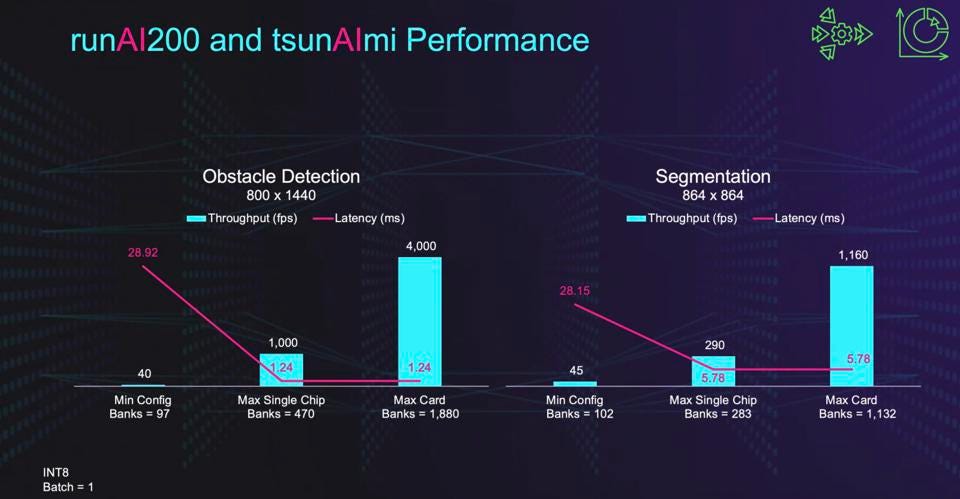
Untether AI’s runAI200 chip has good performance and efficiency, and demonstrates flat latency from 1-4 chips. Untether AI
For applications such as ADAS and mobile autonomy, latency can be as critical as throughput, and Untether seems to shine here. The company is shipping chips, cards, and software by the end of this year to early potential clients.

Untether Cards UntetherAI
In a model akin to that of Cerebras Systems, the UntetherAI platform uses physical spatial allocation of layers across the ocean of cores, the first we have seen in a chip focused on inference processing. This is a key to the excellent power efficiency, as it minimizes costly data movement to and from memory stores.

Untether uses physical allocation for AI models UntetherAI
Conclusions
While a few competitors will claim better power efficiency, none that we are aware of can also claim exceptional inference performance and latency. UntetherAI may be setting a new bar here, and may have significant opportunities in performance-demanding applications such as self-driving vehicles.
There are the usual caveats we always express when opining on startups here, such as product readiness, software (oh, yeah, it take software to build solutions!) and a product roadmap, but one thing is abundantly clear to us: Hardware is fun again!