Of course the answer depends on who you ask.
There is a quiet drama simmering over AI chip benchmarks. This isn’t the first time, and will certainly not be the last. Keeps me busy. This time, it is between Amazon Web Services (AWS) and NVIDIA. It is always NVIDIA. Not because NVIDIA is squirrelly with benchmarks, quite the contrary, but because they are the target. Beat NVIDIA, and you win big, right?
AWS and NVIDIA posted inference benchmarks running the same model, BERT Base, which is a popular, small-ish, natural language model. AWS said they beat NVIDIA. NVIDIA published data quite to the contrary. Could both somehow be right? This tug of war has played out quietly, below most users and investors radars. After all, NVIDIA does not want to confront one of its largest customers.
But we’ve got the analysis here so let’s dive in and see who really is faster and more affordable. The stakes are significant for bragging rights, but we all know that users make infrastructure decisions based on a wide range of criteria; benchmarks are only a small but important part of the calculus.
The Setup
In the recent blog, AWS claimed the home-grown Inferentia chip is up to 12 time faster than the NVIDIA T4 GPU AWS instances, and costs up to 70% less. NVIDIA responded politely and a bit obliquely without making any comparisons, posting a blog showing AWS users how to get the best performance from GPU instances by running the model through and on NVIDIA software. AWS used same open-source HuggingFace PyTorch model on both, while NVIDIA used the model that is optimized for GPUs, and ran the inference processing with NVIDIA tools.
The Data
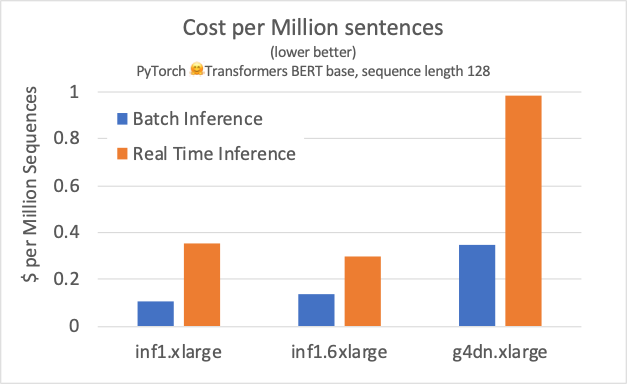
AWS ran benchmarks for both batch and real time (BS=1) inference processing. The results show that Inferentia beat the NVIDIA T4 across the board, at lower cost. By design, this was an “out of the box” comparison, running the benchmarks through the PyTorch framework without any optimizations for either platform using open source models. There is some optimization here that is transparent to the user, in which the Neuron compiler converts 32-bit floating-point to Bfloat16 to preserve precision while improving performance under TensorFlow and PyTorch.
In contrast, NVIDIA engineers used the NVIDIA version of BERT and TensorRT to quantize the model to 8-bit integer math (instead of Bfloat16 as AWS used), and ran the code on the Triton Inference Server to dynamically optimize batch sizes to a desired response time goal (5- and 10-milliseconds). These techniques effectively turned the economics around 180 degrees in NVIDIA’s favor. Instead of costing 88 cents to run a million low-latency sentence inferences, NVIDIA says they can do that under 5 milliseconds for only 8 cents, and can run offline batch inference requests for the same price.
Our Analysis
Here’s our depiction of the results. As you can see, the improvement using Triton and TensorRT was significant. Looking at the raw data on the blog, NVIDIA outperformed all but two Inferentia configurations by a factor 4X to over 6X in raw bandwidth. The Inferentia Inf1.6xlarge with four Inferentia chips, crossed the line with throughput similar to the optimized T4, but at a 4X price premium for BS=1.
The difference between the results and approaches are driven by what each company believes is important to its customers. AWS believes some clients do not want to spend the time to optimize the inference models, in other words, “good enough” is just that, “good enough”. Also, AWS believes many clients are not comfortable that 8-bit integer models can deliver adequate accuracy. On the other side, NVIDIA points to customers who are getting great results on Int-8 models for Auto, medical imaging, smart cities, and increasingly conversational AI, including Tu-Simple, Zoox, and Clarify. We would also mention that while the Inferentia chip itself supports 8-bit integer operations, the compiler does not, reflecting AWS’s dismissal of using 8-bit math based on customer input.
Conclusions
So, what is one to make of all this? If you are willing to optimize your models, and use NVIDIA’s version of the models, NVIDIA appears faster and lower cost. But, if you want to run open-source models “as is” straight from the framework, then AWS appears to win the match-up by a healthy margin.
Comparing NVIDIA performance numbers (using INT + TensorRT + Custom model) against AWS’s (through PyTorch, open source model & Bfloat16) may not be an apples to apples comparison, but running the model on the T4 without optimization is unrealistic. It is like asking NVIDIA to run the race with both legs in a sack.
Independent vendor-run benchmarks invariably invite rebuttals. (See our discussion on AI benchmarking pitfalls here.) The MLPerf benchmarks and MLCommons community help avoid such controversy, and we encourage AWS to consider joining MLCommons.
Large companies and venture capitalists are investing billions of dollars to develop faster AI chips precisely because performance matters. Using models “out of the box” is fine for early prototyping, but if organizations are comfortable deploying these unoptimized results for production at lower performance and higher costs, we would be surprised.