Common Pitfalls In AI Benchmark Claims
Most AI hardware purchase decisions follow lengthy evaluations running models and data representative of the application under development. Thats how decisions are made, and should be made. However, in typical AI hardware marketing, vendors seek an outrageous claim, touting performance that, while sometimes useful, can often confuse an observer. And sometimes these benchmarks claims border on deceit!
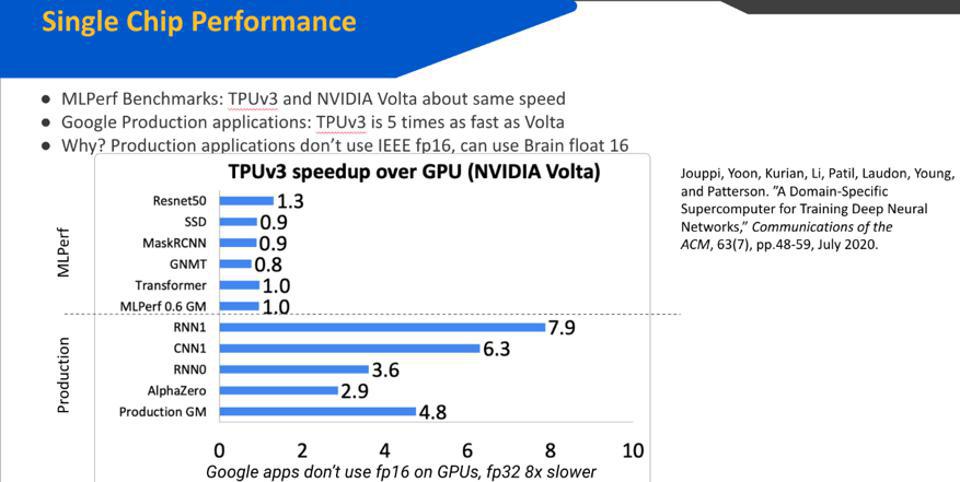
Google claims its TPUv3 is faster than NVIDIA GPUs. But NVIDIA claims its GPU is faster than a TPU. … [+] Google
Here are a few tell-tale signs that something may be missing or even misleading:
- Some vendors cherry-pick AI models for which the competition (usually NVIDIA) has yet to optimize the required software. That may be because there is little market demand yet for these new models.
- Failing to specify prediction accuracy achieved is a common omission: it is easy to beat a competitor if you lower the accuracy bar below the customer’s typical requirements, typically 95% of State-of-the-Art accuracy.
- Some vendors even compare new hardware to older hardware that is not relevant to a recent purchase decision, clearly a blatant foul. Sadly, we have seen companies compare new or forthcoming chips to a GPU with one- or even two-generations old.
- Cloud Service Providers require latencies under a required threshold, such as 6 or 7 milliseconds, however this does not mandate a small batch size. If an accelerator can process a large batch and still meet that threshold, it is fair to compare a run with that platform to a chip that requires, or is optimized for, smaller batch sizes. Note that edge computing and critical real-time systems typically do require smaller batch sizes.
- Many vendors, unfortunately, compare multiple chips to a single chip. Sometimes there are legitimate reasons for what could seem to be a ruse. For example, the Google TPU and Graphcore IPU both use a four-chip platform to deliver its accelerator. But be aware that the comparisons are perhaps not apples to apples. Most customers view performance, price/performance, power, and TCO of the entire hardware stack to be the critical metric (after compatibility with existing software and AI models).
There is a solution: MLPerf
Most, if not all, of these issues, can easily be avoided if and when companies begin to produce and submit results to the standardized MLPerf benchmark organization, MLCommons. (We have a video that may interest you on our website with the Executive Director of MLCommons, David Kanter.) We hope some of the startups will pick up the challenge in 2021. However, many will understandably focus instead on potential client workloads and models.
Cambrian-AI Research considers all performance claims outside of MLPerf with some skepticism because of the issues outlined above. We encourage all our clients and other AI vendors to submit to MLCommons for inclusion in the training and inference benchmarks that are pertinent.
Disclosures: This article expresses the opinions of the author, and is not to be taken as advice to purchase from nor invest in the companies mentioned. My firm, Cambrian AI Research, is fortunate to have many, if not most, semiconductor firms as our clients, including NVIDIA, Intel, IBM, Qualcomm, Blaize Graphcore, Synopsys and Tenstorrent . We have no investment positions in any of the companies mentioned in this article. For more information, please visit our website at
.