NVIDIA is the 800 lb. gorilla in the AI hardware space. The company invests heavily in silicon, systems, and software to maintain that leadership position. This blog is an excerpt from the AI Competitive Landscape Report which is available to subscribers.
Early researchers in AI’s deep neural networks realized that NVIDIA GPUs, which process matrices to create 3D graphics, could be used to accelerate the matrix (tensor) operations needed for AI. NVIDIA quickly appreciated the potential and extended its CUDA software stack to include specific linear algebra libraries required for AI. The result was that the Pascal architecture became the primary platform people were using for AI training as the market initially developed. Fast-forward three generations, and we see that, in the most recent quarter, NVIDIA data center revenue was $1.9B. That is an increase of 160% over the same period last year, reflecting both organic GPU growth and the Mellanox acquisition.
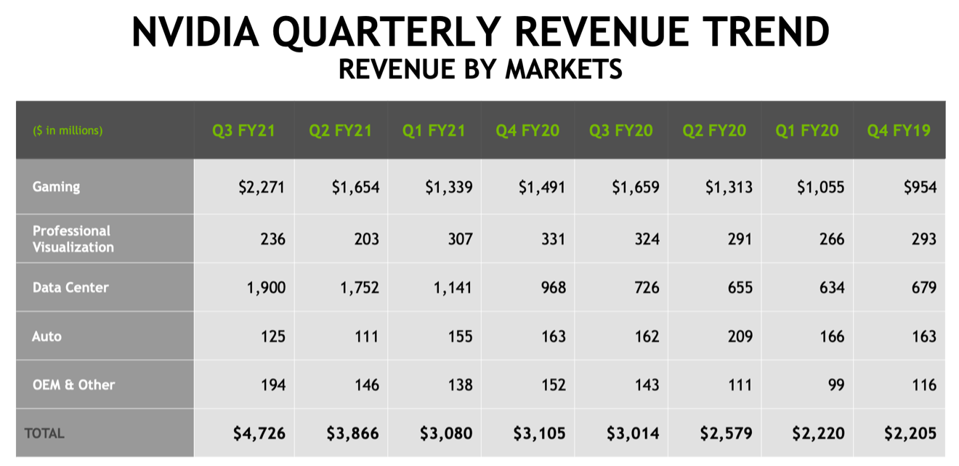
NVIDIA Revenue by segment and quarter. Source: NVIDIA
Last year, the company launched the Ampere-based A100 TensorCore GPU, which replaced the V100 as the fastest chip for deep learning and AI for most models and benchmarks. While many startups will claim performance superior to the A100, I have yet to see any credible benchmarks that support such assertions in chip-to-chip comparisons. NVIDIA delivered the A100 immediately, and it was adopted by most cloud service providers, including Amazon AWS, Microsoft, and Google. NVIDIA has also built Top 50 supercomputers using NVIDIA’s DGX and HGX platforms with A100s and Mellanox networking.
As expected by many, NVIDIA updated the product just a few months later with twice the HBM memory (80GB), using the new HBM2E chips. Big models and tables such as we see in Transformers and DLRM tend to be memory starved on GPUs, so this enhancement significantly improves large model performance (See Figure 9).
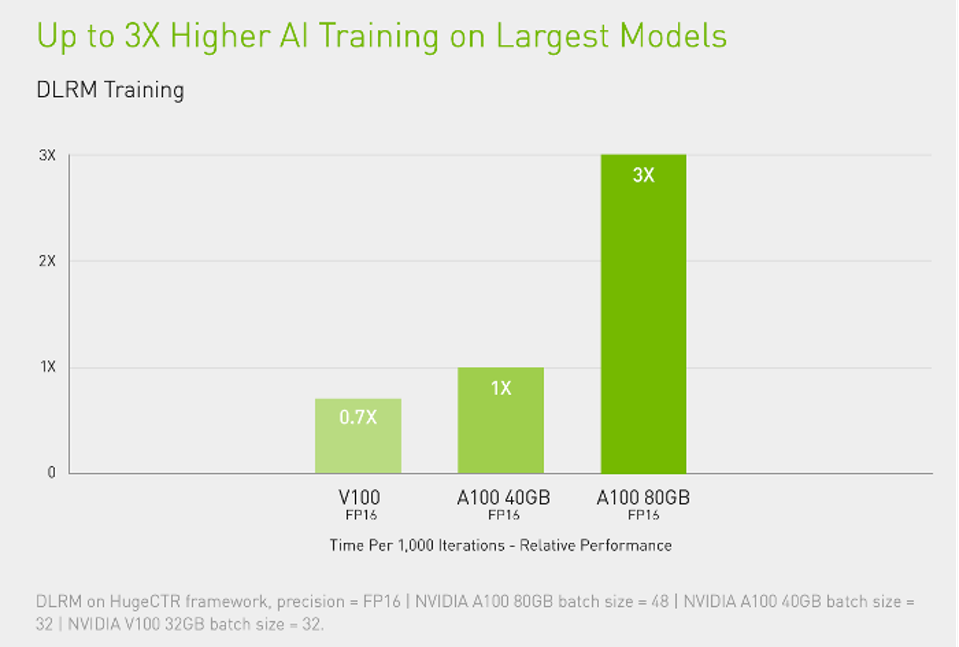
The 80GB version of the A100 can triple the performance of training large models such as the DLRM model for Recommendation Engines. Source: NVIDIA
Ampere is also the GPU engine behind other NVIDIA platforms, including the Drive platform for ADAS and fully self-driving vehicles. By offering a scalable family of Drive platforms, NVIDIA spans the range from a 5W windshield ADAS module at 10 TOPS to the Drive AGX Pegasus for fully autonomous robot-taxis powered by two Orin SoCs and two Ampere GPUs, totaling 2,000 TOPS (!!!) and consuming 800 watts. As a result, NVIDIA now counts Audi, Mercedes-Benz, Toyota, Volvo, and VW as partners. We believe the fear, uncertainty, and doubt concerning NVIDIA’s automotive efforts, instigated in large part by Tesla’s decision to build a chip, are mostly unfounded.

NVIDIA now offers a wide range of platforms for autonomous vehicles. Source: NVIDIA
NVIDIA remains the primary platform for AI in the data center because it delivers high business value. Given the comprehensive and free software stack it supports and the fast time-to-solution it provides, the economics are typically quite favorable. Unlike most alternative platforms, the GPU has excellent single- and double-precision floating-point performance and software stack, making it the go-to-choice for HPC acceleration and cloud services.
The ecosystem and optimized DNN models for GPUs have widened and deepened the CUDA defensive moat protecting NVIDIA GPUs. The software challenges to enable and optimize code for a novel architecture are perhaps the most significant barrier of entry for all contenders entering this market. It can take two to three years to develop the optimized “kernels” (math algorithms) for TensorFlow, Pytorch, etc., for a new chip. Conversely, the NVIDIA GPU Cloud (NGC) offers hundreds of applications with support for containers and certified EGX and HGX platforms.
Every startup will need to undertake this work since the hand-tuned kernels for convolution, pooling, etc., are highly dependent on the specific architecture on which it will execute. And since neural network innovation continues unabated, this effort will be continuous; it is not a one-and-done effort.
Beyond software, we believe that NVIDIA is spending some $250M each year building and supporting its Saturn V, Selene, and other internal supercomputers to enable AI research and chip development. NVIDIA’s clients have also implemented similar internal supercomputing-class AI systems using the NVIDIA DGX/HGX/SuperPod platforms. So, when we think of NVIDIA’s competitive moat, we see it extending far wider and deeper than chips and CUDA.
NVIDIA has repeatedly submitted the highest performance results running the MLPerf benchmark suite for training and inference processing on currently available hardware. However, other chipmakers, notably Google, submitted better results in the “Research” category. MLCommons, the organization that manages the MLPerf process, requires all such members to make these devices available within one year of the research submission or withdraw the results.
In a world full of half-truths, NVIDIA is the pinnacle of transparency regarding performance and has been a strong advocate for MLPerf. Detailed specifications of NVIDIA product performance are here.
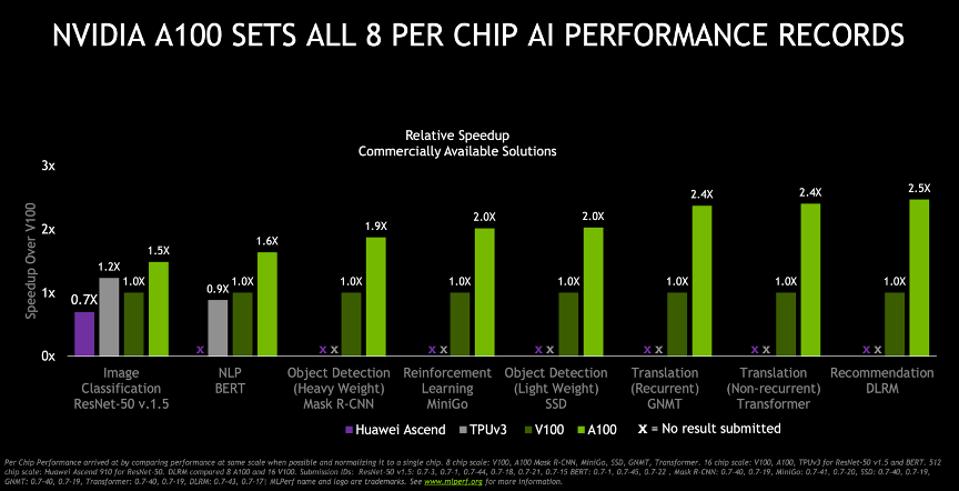
NVIDIA A100 is the fastest production chip in the market for AI today and continues to increase in performance through software. Source: NVIDIA
Some observers question NVIDIA’s ability to compete in inference processing, presumably based on a belief that the GPU is not optimal for running a particular model. However, NVIDIA has repeatedly demonstrated excellent benchmark performance on a wide variety of inference tasks. Furthermore, the new Multi-Instance GPU (MIG) increases the A100’s ability to be dynamically sized to meet model needs most efficiently.
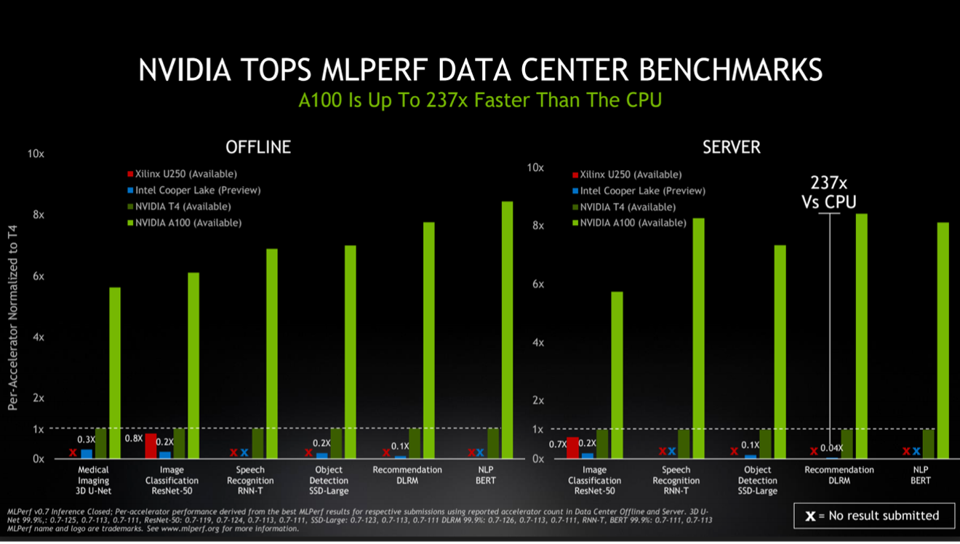
NVIDIA MLPerf benchmarks for inference blow away all competitors. However, there are dozens of competitors who have NVIDIA in their sights. Source: NVIDIA
All startups and potential investors must internalize NVIDIA’s consistent ability to improve performance, both in software and new chips, when projecting expected performance advantages versus the leader. NVIDIA shared a graph with us that shows that the company’s AI silicon platforms and software have increased performance by a factor of four in just 1.5 years. Failing to anticipate this, Nervana had promised to deliver 10X NVIDIA’s performance about the time Intel acquired the startup. However, by the time Intel canceled the project in 2019, Nervana’s performance lead was less than 2X. Now that the A100 is out, the Nervana chip would not be compelling, if even competitive. Software alone improved the V100 performance by anywhere from 10 to 120%.
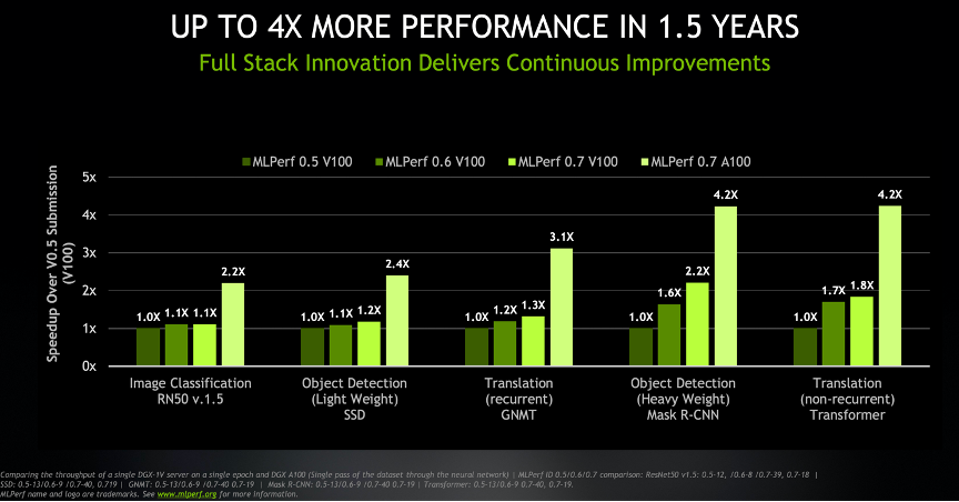
NVIDIA has demonstrated its ability to increase performance year over year with both new hardware and optimizing software. Source: NVIDIA
Of course, we must note that NVIDIA intends to acquire Arm, which would provide Jensen a route to market to monetize IP he does not care to productize. This acquisition could establish NVIDIA as a broad-based supplier of high-performance data centers, platforms, silicon, and IP if approved. The acquisition raises objections, especially from Arm partners who compete with NVIDIA, and closing this deal will be problematic. However, we believe NVIDIA will be just fine even if the deal fails.
Strengths: NVIDIA has built a significant lead in hardware, software, and ecosystem for AI acceleration. Its size and share make them a formidable, if not unbeatable, competitor. There are four reasons why NVIDIA continues to be the leader for #AI in the data center.
1. NVIDIA has high-speed hardware and optimized software that accelerates a wide variety of workloads, not just AI, which increases data center utilization.
2. NVIDIA builds optimized platforms (DGX, HGX, Jetson, Drive) that are easy to deploy and include AMD or Intel CPUs and Mellanox networking.
3. NVIDIA nurtures and benefits from a massive ecosystem of cloud service providers, software, and researchers worldwide
Finally, note that cloud service providers prefer the NVIDIA GPU, as it accelerates Deep Neural Networks, HPC, and Machine Learning, improving the CSP’s utilization rates and profitability.
Weaknesses: NVIDIA has decided to stay with its single architecture strategy while adding specific features for important markets like gaming, HPC, and AI. We believe it is true that a chip that only supports a few workloads could be theoretically faster. However, it is essential to note that while this thesis from most AI startup venture pitches is intriguing, it indeed has been belied by NVIDIA’s actual performance and results.
Disclosures: My firm, Cambrian AI Research, is fortunate to have many, if not most, semiconductor firms as our clients, including NVIDIA, Intel, IBM, Qualcomm, Blaize Graphcore, Synopsys and Tenstorrent. We have no investment positions in any of the companies mentioned in this article.