Intel Habana Labs and Graphcore add scale and software optimizations, while Google skips this round, choosing to put a stake in the ground for half-trillion parameter models.
Every six months, the AI hardware community gathers virtually to strut their hardware stuff and find a way to claim the pole position in the multi-billion dollar market for AI training infrastructure. At first glance, the MLPerf v1.1 results appear to tell the same-old story of NVIDIA dominance, but there are many axes along which to evaluate the reams of data.
Let’s look at what the latest MLPerf training benchmarks can tell us.
NVIDIA still wins all AI benchmarks in spite of $Billions being spent by others to catch up
Let’s start by looking at the indisputable leader, NVIDIA, which has attracted the lion’s share of AI Data Center revenue and once again swept the MLPerf table based on per-chip performance and total time to train (TTT). NVIDIA’s benchmarks are impressive, fueled by a constant improvement in software and model optimization, tuned specifically for the A100 GPU. TTT may represent the ultimate performance measurement, but chasing it can cost a fortune and may not be relevant to most AI installations. After all, training tiny models like Resnet on over 4000 GPU’s in order to claim the fastest hardware crown is irrelevant in the real world. Rather, TTT is a demonstration of scalability, which is universally important to AI practitioners.
NVIDIA’s performance leadership was demonstrated across a wide range of configurations and the full complement of workloads, led in part by teamwork with Microsoft Azure using the new NDm A100 V4, now the fastest cloud AI instance anywhere. In addition, early every global computer vendors submitted multiple MLPerf records.
While the A100 is approaching its second birthday next May, NVIDIA has delivered 5X more performance with full stack software optimization in the last year alone, and more than 20X in the last 3 years. Consequently, competitors that assert future performance goals of 10X over NVIDIA’s current hardware may mislead potential investors; such a claim 3 years ago (the typical development cycle for such chips) has already been more than wiped out by new hardware and software optimization. (Does anyone remember Nervana?)
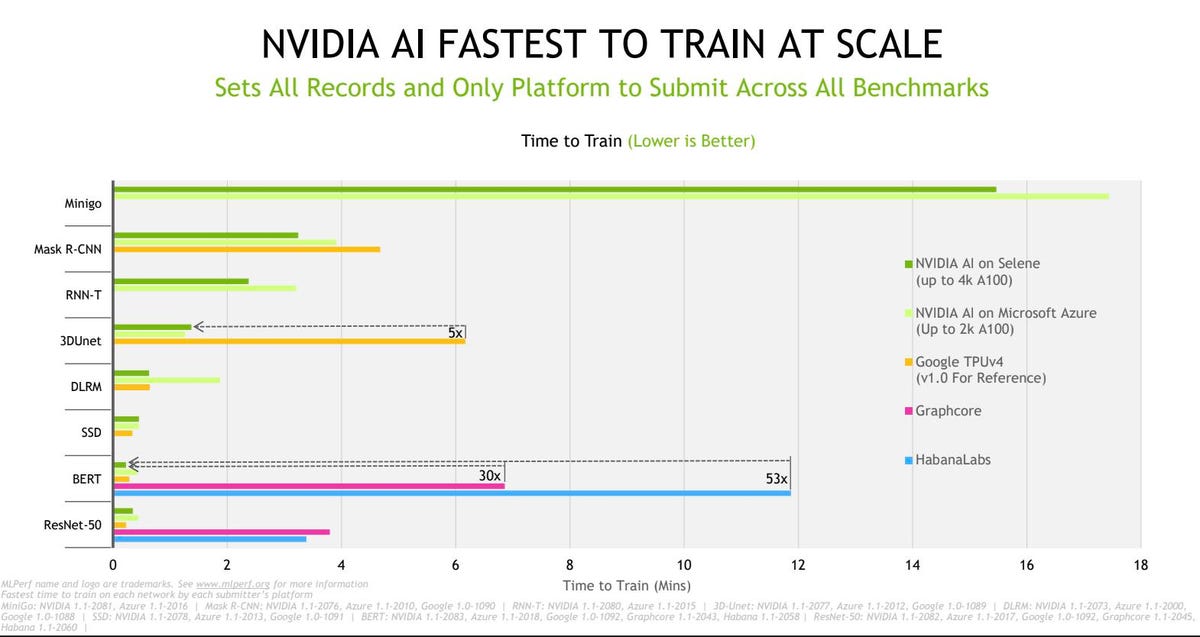
NVIDIA has provided this chart depicting Fastest TTT across all eight MLPerf benchmarks except one (Google TPU-V4, MLPerf V1.0). Lower is better. NVIDIA
Looking at the graph above, one can appreciate NVIDIA’s leadership position. However, keep in mind that TTT is not an apples to apples comparison; Selene has over 4000 GPUs, so comparing it to smaller Habana and Graphcore configurations is really about the scalability of NVIDIA’s hardware and software, not a statement about relative chip performance. So, let’s look at it from that perspective.

NVIDIA dominates the per-chip performance as well with one exception: the upcoming Google TPU-v4 NVIDIA
Once again, NVIDIA’s somewhat more costly chips win the day; HBM2e memory contributes to performance but entails a much higher cost.
However, businesses don’t buy a supercomputer like Selene, nor a single GPU to run AI. So we built the following chart comparing a reasonable server configuration of 64-chips running BERT NLP and Resnet image processing. Each bar compares a 64-way cluster versus the leader, specifically NVIDIA A100 for BERT, and Google TPU-v4 (MLPerf 1.0) for Resnet. Here, once again, NVIDIA is impressive, with far better performance versus Graphcore IPU and Intel Habana Labs. Only Google TPU-v4, which is not yet commercially available on the Google cloud, is faster than NVIDIA (by 38% for Resnet) based on the V1.0 results Google published last June.
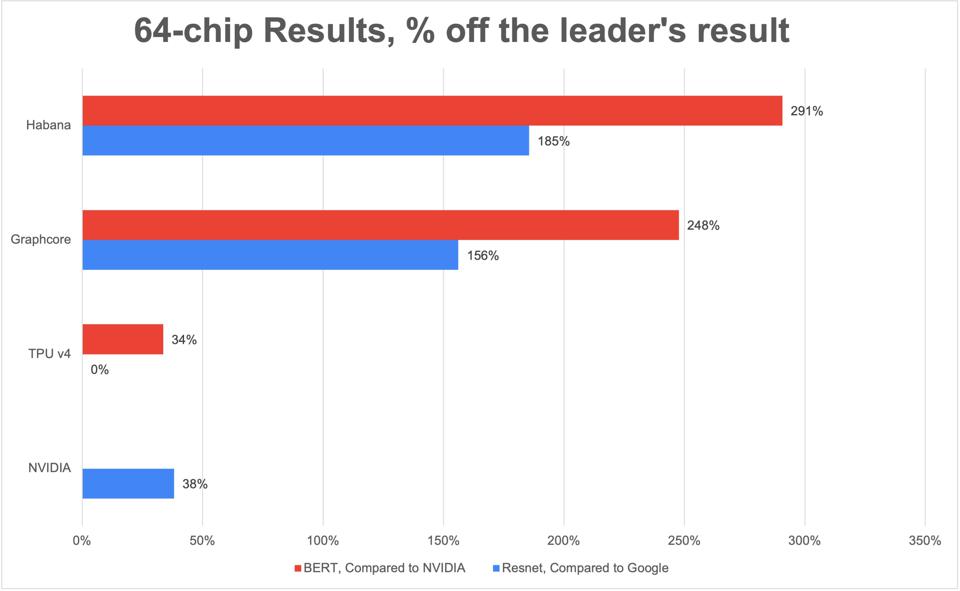
Comparing benchmark results for 64-accelerator configurations for image and language processing, expressed as a percentage slower than the best posted. For example, Habana Labs is 291% slower than NVIDIA on a chip-to-chip comparison. Cambrian-AI Research
But there is another way to dice the data. And Graphcore is happy to help.
OK, so NVIDIA wins nearly every comparison, with Google in the hunt, right? Not so fast! Graphcore, which has dramatically improved their Poplar software stack and leveraged the open software community they have nurtured, demonstrates a same-size server node of 16 IPUs vs. 8 GPUs, and they are roughly equivalent, at least for Resnet. After all, these are the compute chunks people actually buy, one server at a time. And while Graphcore rightly claims their 16-IPU pod costs roughly half that of a gold-plated DGX, Supermicro, HPE, Lenovo and Dell would point to their more affordable servers, sans gold.

Graphcore’s 16-chip IPU-Pod16 is comparable to an 8-GPU NVIDIA DGX, thanks to a 23% improvement in Graphcore software optimizations. Graphcore
Habana Labs and Graphcore quantify performance at scale
In the V1.0 release, Habana Labs performed on a small configuration, and did not engage in any software optimizations. The result was a bit of a yawn. This time around, however, the team improved on both axes, demonstrating near linear scalability thanks to the Gaudi chip’s 100Gbe ports, and nearly doubling the performance of BERT-Large for NLP with software optimizations. Based on a discussion with their benchmark leader, I expect many more to come.

Intel Habana Labs continues to show progress in both performance and scalability. Habana Labs
On the Graphcore front, we saw both significant software improvements and more demonstrated scalability. Since the last MLPerf submission, the UK-based unicorn has released IPODs with up to 256 IPU’s, and the benchmarking team quantified excellent scalability. This should put to rest any questions about the IPU Machine ability to scale well. We look forward to seeing more such proof-points in the future.
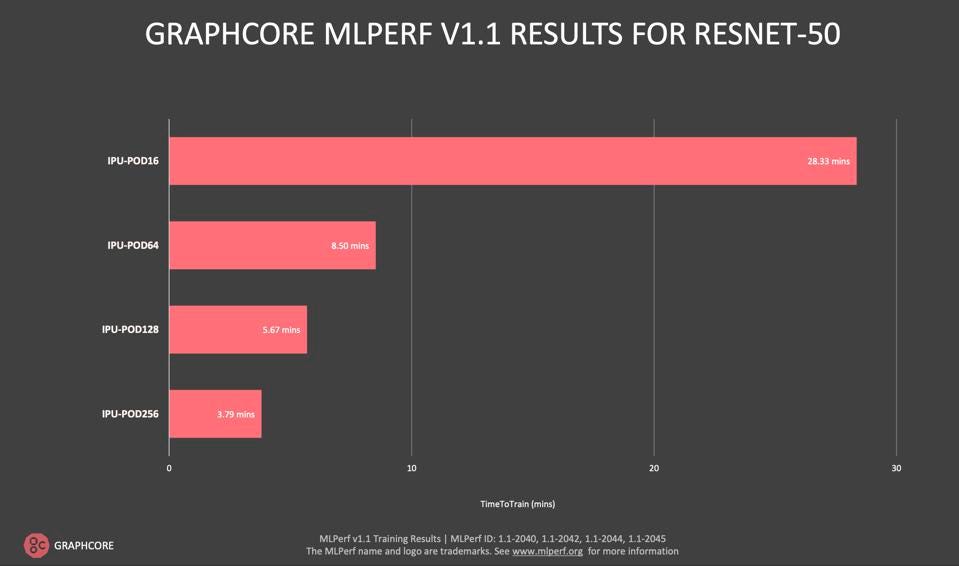
Graphcore demonstrated excellent scalability up to 256 IPUs. Graphcore
On another front, Graphcore touted the somewhat unique disaggregated data center architecture, wherein the system can be configured dynamically or physically to an optimal CPU/accelerator ratio. This approach can greatly simplify and reduce the cost of data-center scale AI. We will dive more deeply into the benefits of this approach in an upcoming blog, but it certainly seems appealing.
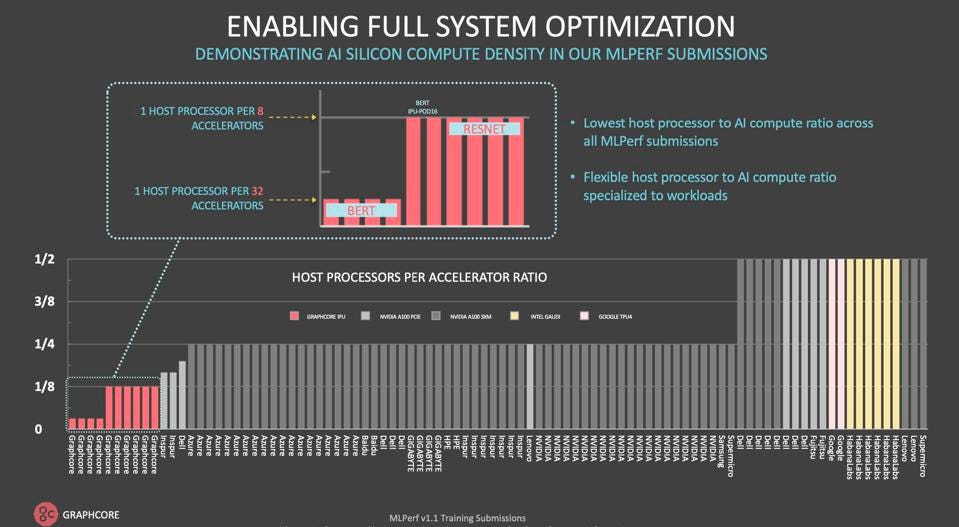
Graphcore compared their ability to use fewer host processors than their competition. Graphcore
Google decides to play its own game: Large Model training
Google decided to skip the standard benchmarks (closed division) this time around, focusing instead on running two benchmarks for massive NLP models, both considerably larger than GPT-3. The engineering team ran a 200 and 480 billion parameter transformer on large clusters (1024 and 2048 nodes) of the upcoming TPU-v4 accelerators. The models were trained in roughly 14 and 20 hours respectively, a hugde improvement over the weeks and months previous large models have required. Large AI models will form the foundation of the next generation of AI, so Googles decision makes sense to us. We have created this short video to help explain what all the fuss is about.
Conclusions
As always, parsing of MLPerf data is an art form in which vendors can chose which benchmarks to compare and at what scale. Scalability and software optimization are absolutely huge; one reason we don’t expect to see Amazon AWS nor AMD added to the mix any time soon, if ever. I sincerely hope I am wrong. Graphcore and Habana made excellent progress on both fronts in the v1.1 round. And we hope to see more benchmarks, especially DLRM for recommendation engines, from Graphcore and Habana in future releases. Only NVIDIA runs them all. And we certainly hope to see udpated results from Google in the closed division; we assume the organization has made significant progress in TPU-v4 software optimization.
The new results, however, continue to point to NVIDIA’s massive leadership, not just in hardware performance but in the massive ecosystem their engineers and followers have developed. That lead, in our opinion, will continue to outpace additional hardware innovations their challengers will throw at them.
Finally, we would be remiss if we did not congratulate the entire cross-industry team and the MLCommons organization for all the hard work and careful peer reviews that make these benchmarks so valuable to the industry.