Ok, while that is hardly surprising news, given the comfortable lead NVIDIA enjoys, Google’s upcoming TPUv4 out-performed NVIDIA on three of eight benchmarks on a chip-to-chip basis, while Graphcore’s performance and price/performance is in the ball park.
Meanwhile, Intel’s Habana Labs, the newest kid on the block, has work to do on software, however the Amazon AWS win will spur development of an AI ecosystem. Let the Cambrian Explosion of AI begin in earnest!
Benchmarks alone rarely if ever determine who will win a sale, but they do provide more than just bragging rights. The benchmarks can show how many AI application models are ready for prime time on available platforms, while demonstrating improved maturity and performance of vendors’ AI software. The benchmarks also provide a valuable test bed for vendors to debug and optimize their platforms. To this end, MLCommons has released a new slate of AI training performance benchmarks that provide insights about how well Graphcore, Google, and Intel’s Habana Labs are prepared to compete against NVIDIA in a market that may grow to over $25B over the next five years, according to Gartner.
As we have seen before, few companies have been willing to dedicate the required resources to run the standard AI benchmarks for two primary reasons: 1) many feel their efforts are better spent working on customer opportunities, and/or 2) their chips would fare poorly against NVIDIA. But this time around, Habana and Graphcore joined Google in challenging NVIDIA’s leadership. Let’s take a deeper look.
MLPerf Training v1.0 Results
The benchmark suite for training included a few adjustments to reflect the changing landscape of AI workloads, but the big news is that Graphcore, Habana, and Google stepped up to the plate, and all are to be commended for their contributions and openness. There are 8 benchmarks, and submissions are categorized as Open or Closed, referring to the degree of flexibility afforded in the software used to run and optimize the benchmarks. Submission are also categorized as platforms that are commercially available, or in “preview” for chips not yet generally available, and in “research” for chips still in development.
How is one to evaluate the thousands of cells in a the MLCommons thousands of spreadsheet cells, provided by system vendors such as Dell, Supermicro, Lenovo, NVIDIA Gigabyte and others? The key metric here is the “time to train” 8 models to the prerequisite accuracy, roughly the threshold of human cognition. Then one must decide how to compare the results across a wide range of deployment options and how to normalize these results to provide the desired head-to-head comparison: per chip, per server, or per cluster.
NVIDIA prefers you to look at the per-chip performance and the performance of models at scale, up to 4096 GPU’s in supercomputer, while Graphcore, Google, and Habana would prefer that you compare accelerators, whether it is built with one chip or four and results at significant scale. Since NVIDI’s chip is about as large as can be manufactured, and comes with up to 80GB of fast HBM2E memory, a chip-to-chip comparison favors GPUs. And as we will discuss, the market is maturing to the point where price will finally matter as well as performance: until now, NVIDIA has really not faced any serious competition.
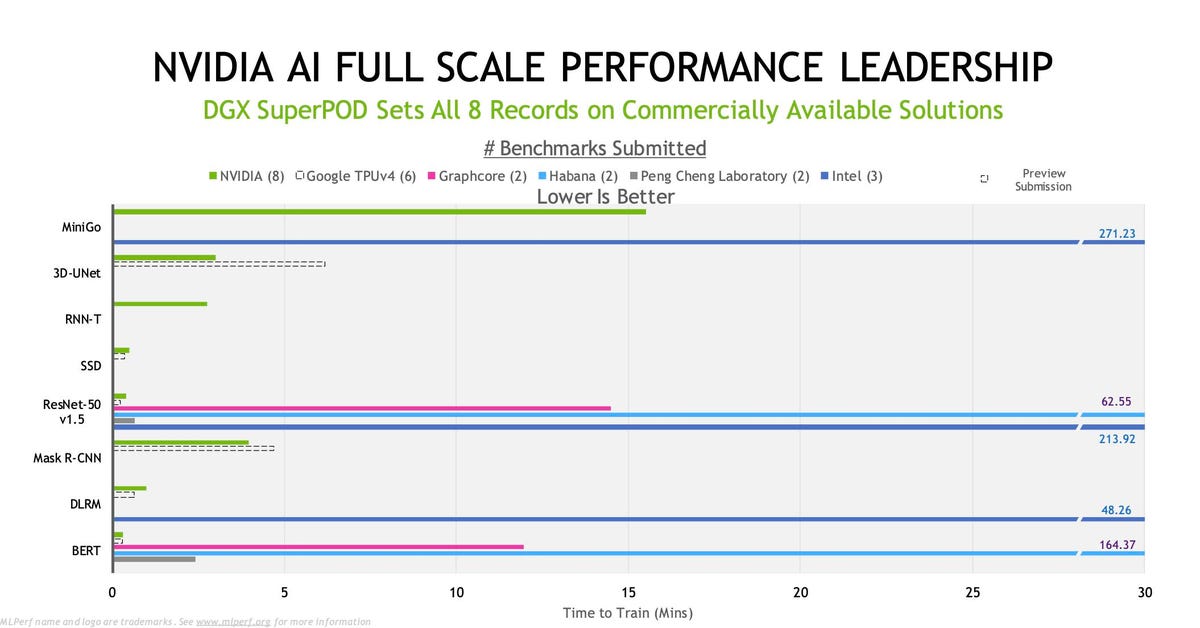
The figure above shows the normalized chip-to-chip performance across the eight MLPerf benchmarks. NVIDIA was the only company to publish results for all eight, and won all eight when compared to Graphcore and Habana Labs. Google TPUv4, expected to be available later this year, won three benchmarks by ~25%, while Graphcore performance is impressive when comparing an IPOD16 to a 4-GPU DGX, especially when one looks at their Open and the IPOD64. Consequently. the company has earned the right to be considered as an attractive alternative.
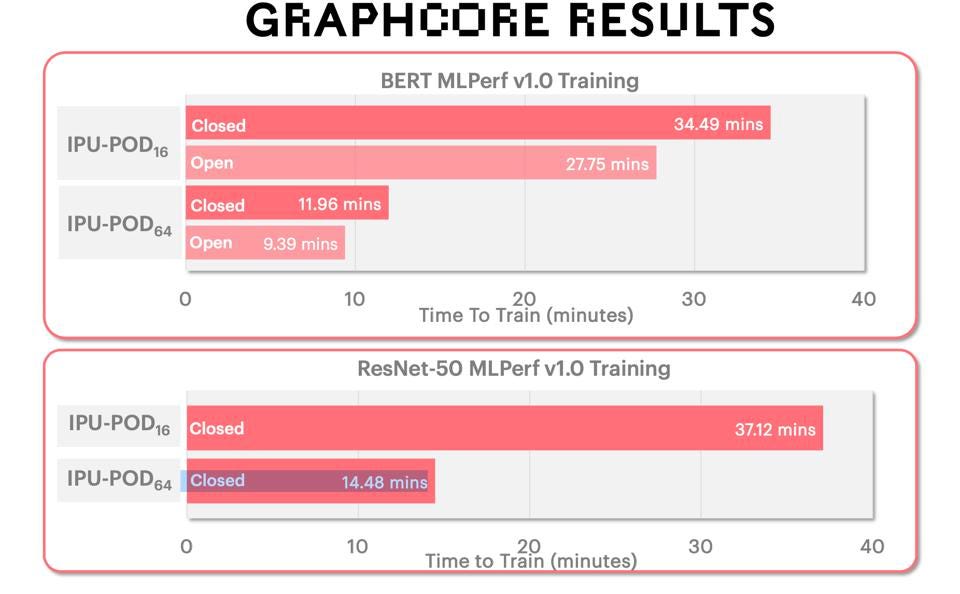 Graphcore results for MLPerf 1.0 training benchmarks demonstrate the significant value of software Graphcore
Graphcore results for MLPerf 1.0 training benchmarks demonstrate the significant value of software Graphcore
Training an AI model is an astoundingly demanding computational workload. Even the world’s largest commercial supercomputer, the 4096-GPU NVIDIA Selene, would take two weeks to train the GPT-3 natural language model pioneered by Open/AI. And even the challenging MLPerf benchmarks seem like toys next to production AI and Microsoft; the BERT model in the MLPerf suite is 1/50th the size of a “real” natural language model. Consequently, while NVIDIA’s chip level performance is impressive, results at larger scale are more relevant to most buyers.
Before we move on to discuss price/performance, it is worth noting that ongoing improvements in software deliver significant performance benefits, as shown by the following data from Graphcore and NVIDIA. In fact, the relatively poor showing by the Habana Labs Gaudi platform is due to the immaturity of the Habana software stack. We expect this platform to show dramatic results in future MLPerf benchmarks, especially as a software ecosystem will be enabled by the upcoming AWS cloud deployment announced last December.
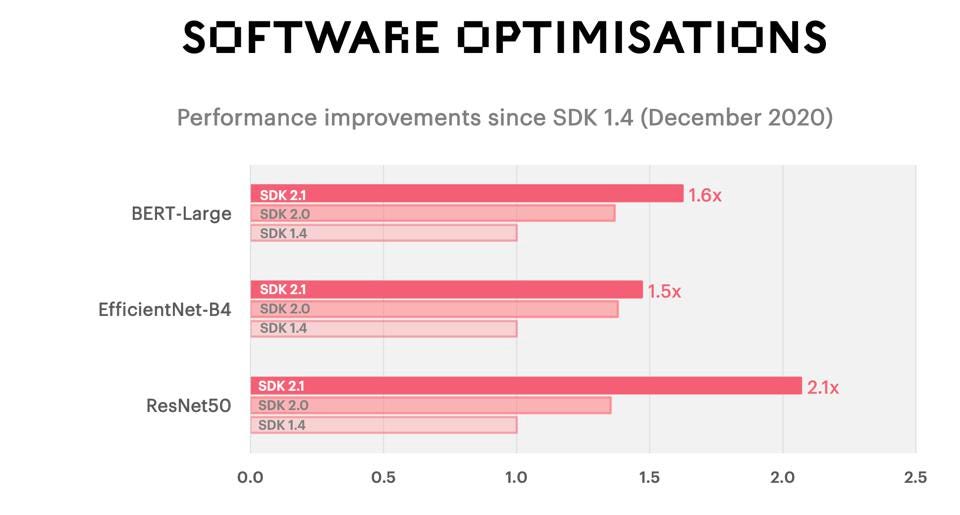 Graphcore has also significantly increased performance as the company’s software stack matures. Graphcore
Graphcore has also significantly increased performance as the company’s software stack matures. Graphcore
The software improvement are especially evident in enabling higher performance at scale, as NVIDA demonstrates on the DGX SuperPOD with up to a 3.5x improvement in just the last year.
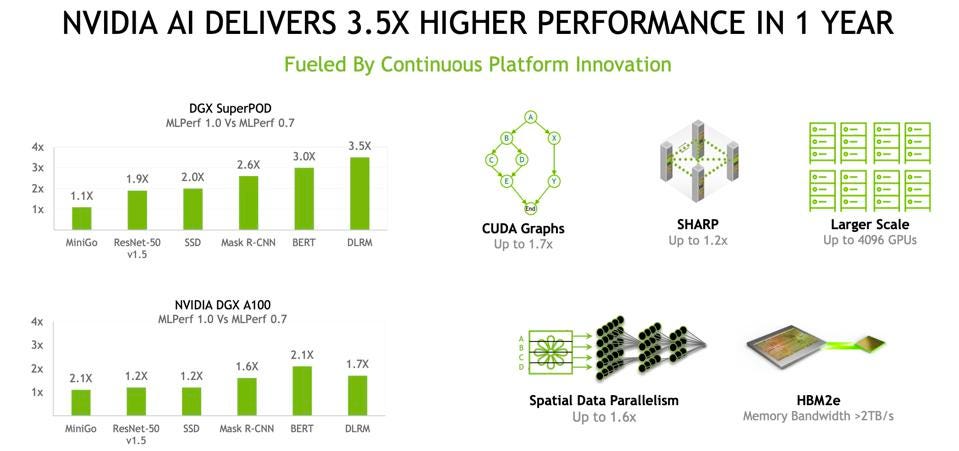 NVIDIA continues to enhance performance of the A100 platform through software, scaling, and memory. NVIDIA
NVIDIA continues to enhance performance of the A100 platform through software, scaling, and memory. NVIDIA
Price/Performance: The Emerging Metric of Merit
As the AI market matures, or at least gets out of the 1st inning, competition will quickly turn to affordability, not just performance. Graphcore’s MLPerf results and $150K price point enable it to deliver better price/performance compared to an NVIDIA DGX by up to 60% on ResNet-50 and 30% for BERT. However, the DGX is literally the industry’s gold standard, complete with a real gold bezel; no cost was spared in delivering the best the industry can offer. So, if one compares, say a Supermicro server with four GPUs to the Graphcore IPU-POD16, NVIDIA delivers some 30% better performance at a lower price, resulting in a 40-50% better price performance.
 NVIDIA and Graphcore disagree as to the appropriate comparison basis for price performance. Vs, DGX … [+]Cambrian-AI Research
NVIDIA and Graphcore disagree as to the appropriate comparison basis for price performance. Vs, DGX … [+]Cambrian-AI Research
Conclusions
All of this is interesting to us chip nerds, but let’s review the bidding of what really matters to buyers of AI hardware or cloud services. In addition to performance and price, customers value scalability, ease of deployment, ease of optimization, availability of the latest models, having a choice of system vendors, and a constantly evolving software stack to enable future models and performance enhancements of the platforms that will be in use for the next three to five years. While the benchmark results from Graphcore, Google, and Habana are excellent and a welcome addition to the AI hardware landscape, NVIDIA will maintain an advantage on these other buying considerations for a considerable time to come.